
Development of a coastal wave emulator using new technologies
How can we achieve global coverage and locally relevant coastal wave estimates? Deltares experts Fedor Baart, Martin Verlaan, Guus van Hemert and former Deltares expert Anna van Gils utilised new technologies to develop a coastal wave emulator. In this blog Fedor Baart explains about the development of this simulator.

What are coastal waves?
Coastal waves are the waves you see when you go out to the sea. The wind generates waves by shearing over the water's surface. Large waves can form if the wind pushes water over a long stretch. These waves then roll towards the coast, where they "feel" the seafloor. As waves begin to feel the seafloor, they will turn towards the beach and can break as they reach shallow water.
What is a coastal wave emulator?
The traditional approach to coastal wave prediction uses computer models to simulate the physics of this process. We can use these models to predict waves several days ahead or for the next decades for climate scenarios.
One complex part about coastal waves is that they are hard to compute. It can take several hours to predict the sea state in a large region. That works for a few days ahead if you want to do this for a few days ahead, but it becomes a very compute-intensive job for decades-long simulations. Many applications ignore coastal waves, use simplified approaches using empirical formulas, or only focus on small regions.
An emulator takes an alternative implementation. If you can collect a large enough dataset of model runs and or observations, you may not need to run a simulation. Your old model runs and measurements allow you to learn how waves will likely propagate. Using a machine learning model that learns the physical rules is an alternative to the physical-based model. The geoscientific field refers to this machine-learning approach as an emulator. Other terms include a surrogate model (as opposed to the "real model" that you prefer) or a data-driven model.
How did you set up this wave emulator?
Creating an emulator consists of several steps. The figure below shows the main tasks and the actions involved per task.
- The first task is to define the application. Here we focus on creating estimates for the total wave energy that reaches the beach over decades. Future coastal erosion estimates need this information. If wind directions change, this can cause specific stretches of coast to suffer from more and other regions to have less coastal erosion.
- The second step is to select relevant input information. As input, we use the wave energy of global ocean wave models. Wave models with global coverage (e.g. Wave Watch III) typically provide coarse waves at the boundary of the coastal sea. We also have information on the bathymetry near the coasts. The EMODNET and GEBCO bathymetries have European and global coverage.
We generated a dataset of wave simulations by using a sampling approach for the parameters and data from bathymetries. The SWAN computer model was used to run a wave simulation for each sample. A sampling strategy is a method of creating a dataset. It involves selecting sea level and wave spectra (a combination of waves with different heights and wavelengths from various directions) as input parameters for the global wave models. We prioritize sampling extreme combinations (e.g. high wave height and low sea level, high wave height with highest sea level) to ensure our emulator is exposed to a broad range of inputs.
Which dataset did you use for training?
We ran a series of 20,000 model runs to create a representative training dataset. The Dell Technologies HPC cluster in Frankfurt provided the computation power and batch system to run all the jobs. We packaged the computer model in a docker container and ran it using singularity without noticeable performance overhead. The dataset consists of example inputs and outputs, as seen in the figure below. The inputs consist of wave information in 256x256 arrays (bathymetry, wet/dry mask) and scalar input parameters (water level, significant wave height at the boundary, wave direction). The output examples included significant wave height, wave direction and period. Part of the data is set aside for testing and validation purposes.
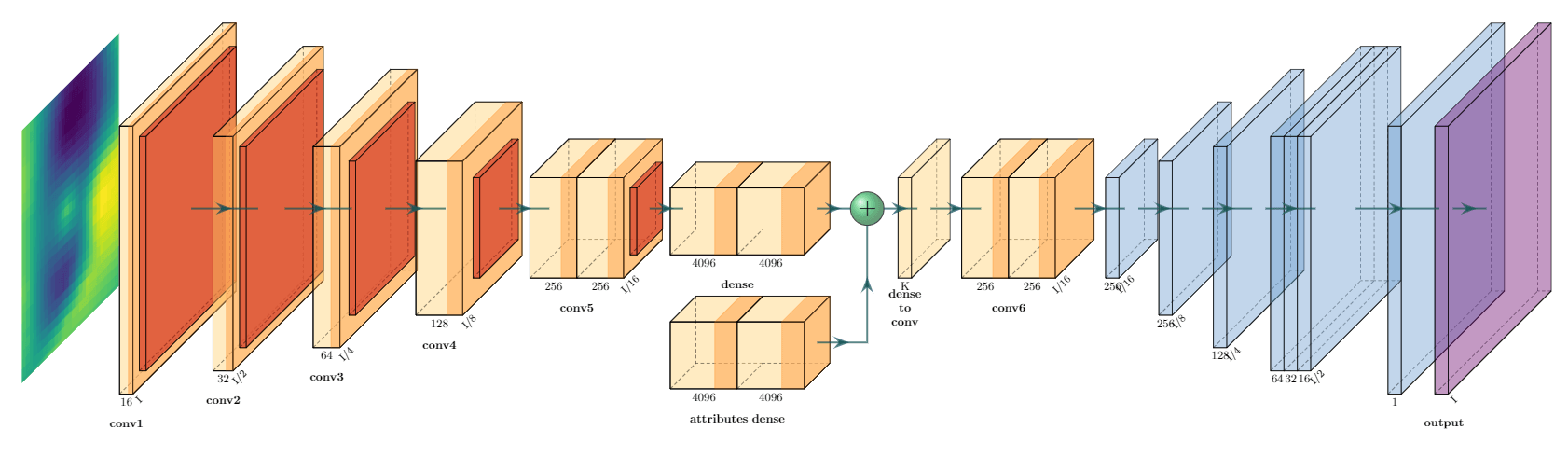
Once you have a dataset of representative model runs, you need to set up a machine-learning model that can transform the example inputs into outputs. Guus van Hemert helped set up and test this model as part of his internship for applied mathematics. Here we used a basic Convolutional Neural Network, similar to what you would use for image recognition. The figure below shows the network architecture.
Why did you use this platform?
Dell Technologies approached us during one of their Innovation sessions, to test out the new Graphcore IPU platform. We were able to use IPU’s (model MK2) with 900MB in processor memory and 1472 cores. The available exchange memory was 526GB. We're always looking for more computation power. Especially during the "model setup" phase, it is essential to have fast-running, tensor-focused processors, like the Intelligence Processing Unit (IPU). Access to a modern processor allows us to iterate more often and thus create better models. Dell Technologies also provided access to their Frankfurt HPC cluster. We generated the dataset, which on one computer would take over 80 days to compute, within a wall clock time of a few days. Because the IPU had a Tensorflow SDK, we could use our existing skills and hardware to test and design the initial models. Graphcore provided the support to tweak the model performance to the specific qualities of the processor.
Why did you make a wave emulator?
There are many different where you need wave information available. There is offshore construction on all the new wind farms. They need information on workability windows in the next few days, but also in the future for the planning of projects. There is marine spatial planning where areas get reallocated. If ships sail a new route, you need wave information to estimate safety. You also want to know how much wave energy reaches the coast under rising sea levels.
Waves are hard to compute because they have extra dimensions. Most environmental processes consist of a quantity (i.e. wave height) varying in space and time. Waves also spread out in frequency and direction.
We now have the wave emulator as a fast alternative to the traditional numerical model.
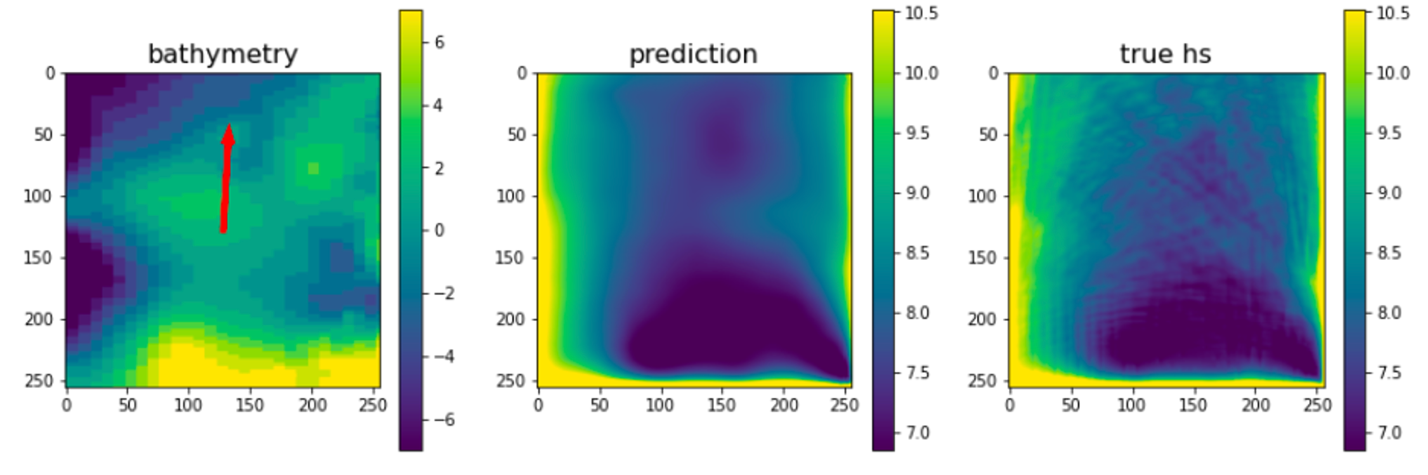
How well does it reflect the numerical model?
The wave model creates comparable results to the model that we emulate. As performance indicators we look at accuracy, runtime and training time. The current average error (RMSE) between the "true" SWAN model versus emulator model, for the output variable significant wave height, for unseen data, is 0.3m. The runtime speedup for a 2560x2560m grid of 10m resolution was a factor of over 1000 (where the SWAN model ran on a CPU). We also compared the training time of the IPU with TPU processors (also processors intended for deep learning). We were able to train our models in 40-75s per epoch compared to 180-400s per epoch on TPUs, thus roughly a factor 4 performance improvement for this dataset / network combination.
Where would you use an emulator?
The traditional focus of wave models has been to assess operational forecasts. As there is now much more construction activity in the nearshore (nourishments, wind farms) and more concern about the effect of waves on the coast (due to anticipated sea-level rise), we need new models. People now expect models to be usable in Digital Twins and design tools (where models need to be interactive) in global assessments. The wave emulator makes this possible.